| country | date | longitude | latitude | region | income_level | CO2_hab | GDP_hab |
|---|---|---|---|---|---|---|---|
| Angola | 1990 | 13.24200 | -8.81155 | Sub-Saharan Africa | Lower middle income | 0.0004317 | 947.7042 |
| France | 1990 | 2.35097 | 48.85660 | Europe & Central Asia | High income | 0.0064512 | 21793.8426 |
| India | 1990 | 77.22500 | 28.63530 | South Asia | Lower middle income | 0.0007090 | 367.5566 |
| Senegal | 1990 | -17.47340 | 14.72470 | Sub-Saharan Africa | Lower middle income | 0.0004229 | 961.5739 |
.
.
Les statistiques bivariées
| country | date | longitude | latitude | region | income_level | CO2_hab | GDP_hab |
|---|---|---|---|---|---|---|---|
| Angola | 1990 | 13.24200 | -8.81155 | Sub-Saharan Africa | Lower middle income | 0.0004317 | 947.7042 |
| France | 1990 | 2.35097 | 48.85660 | Europe & Central Asia | High income | 0.0064512 | 21793.8426 |
| India | 1990 | 77.22500 | 28.63530 | South Asia | Lower middle income | 0.0007090 | 367.5566 |
| Senegal | 1990 | -17.47340 | 14.72470 | Sub-Saharan Africa | Lower middle income | 0.0004229 | 961.5739 |
Source : Banque Mondiale, 1990
Source : Cours de CAR1, Cartographie thématique & Sémiologie Graphique, EE2023
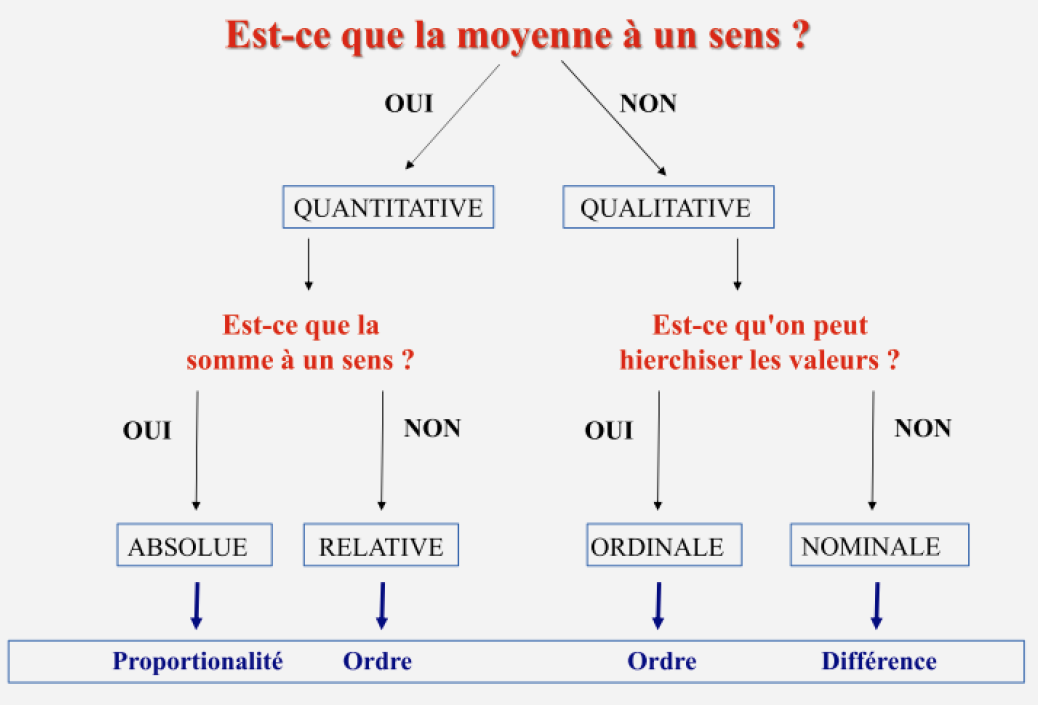
Relation statistique et causalité
Relation statistique : déterminer si la variation d’une variable “dépend” / est fonction de la variation d’une autre.
Attention : la mise en évidence d’une relation ne signifie pas l’identification d’une cause et de son effet, elle signale seulement une co-variation, qu’il reste à interpréter.

Relation statistique et causalité
Relation statistique : déterminer si la variation d’une variable “dépend” / est fonction de la variation d’une autre.
Attention : la mise en évidence d’une relation ne signifie pas l’identification d’une cause et de son effet, elle signale seulement une co-variation, qu’il reste à interpréter.

Relation statistique et causalité
Variété des liens
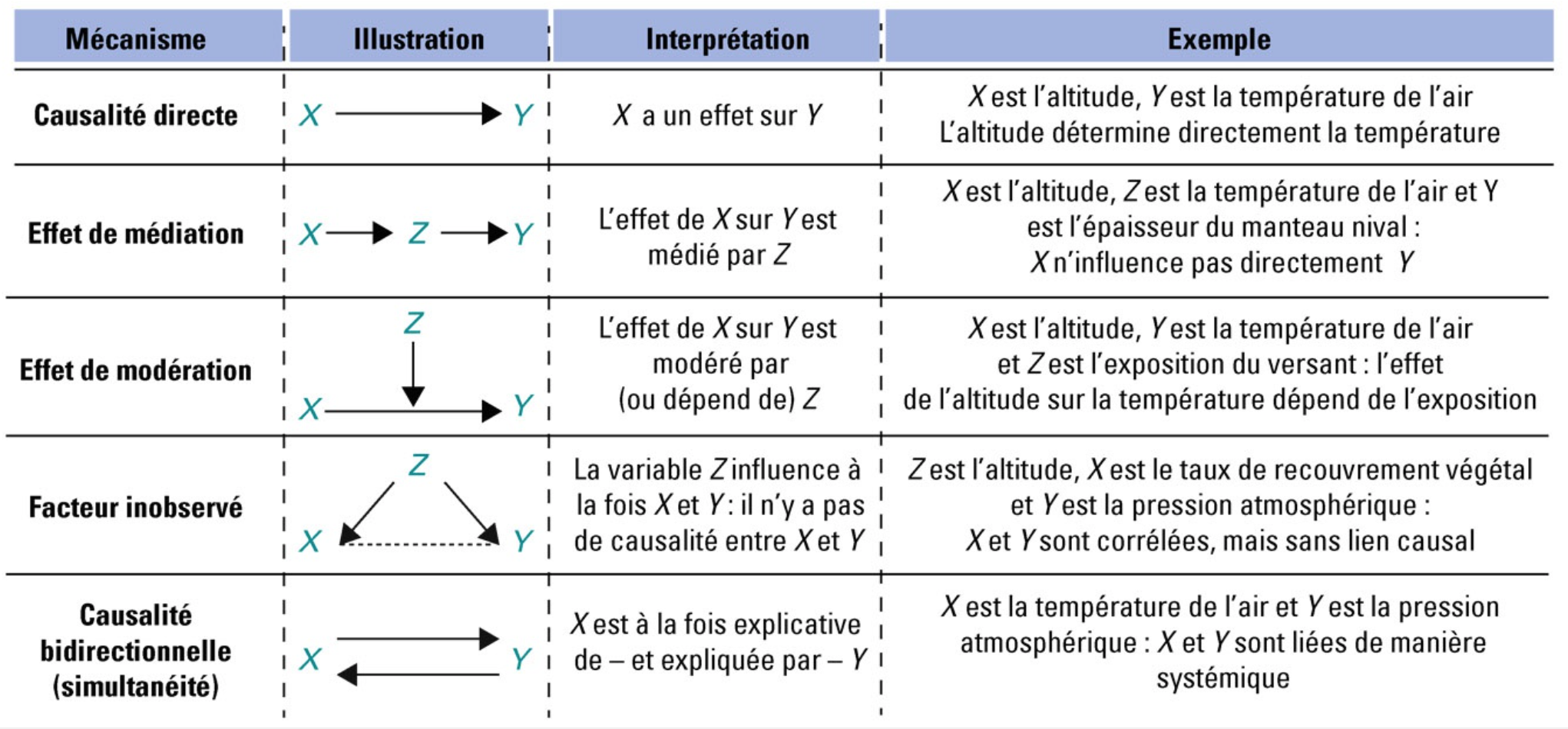
Feuillet, T., Cossart, É., & Commenges, H. (2019). Manuel de géographie quantitative : Concepts, outils, méthodes. Armand Colin.
Relation statistique et causalité
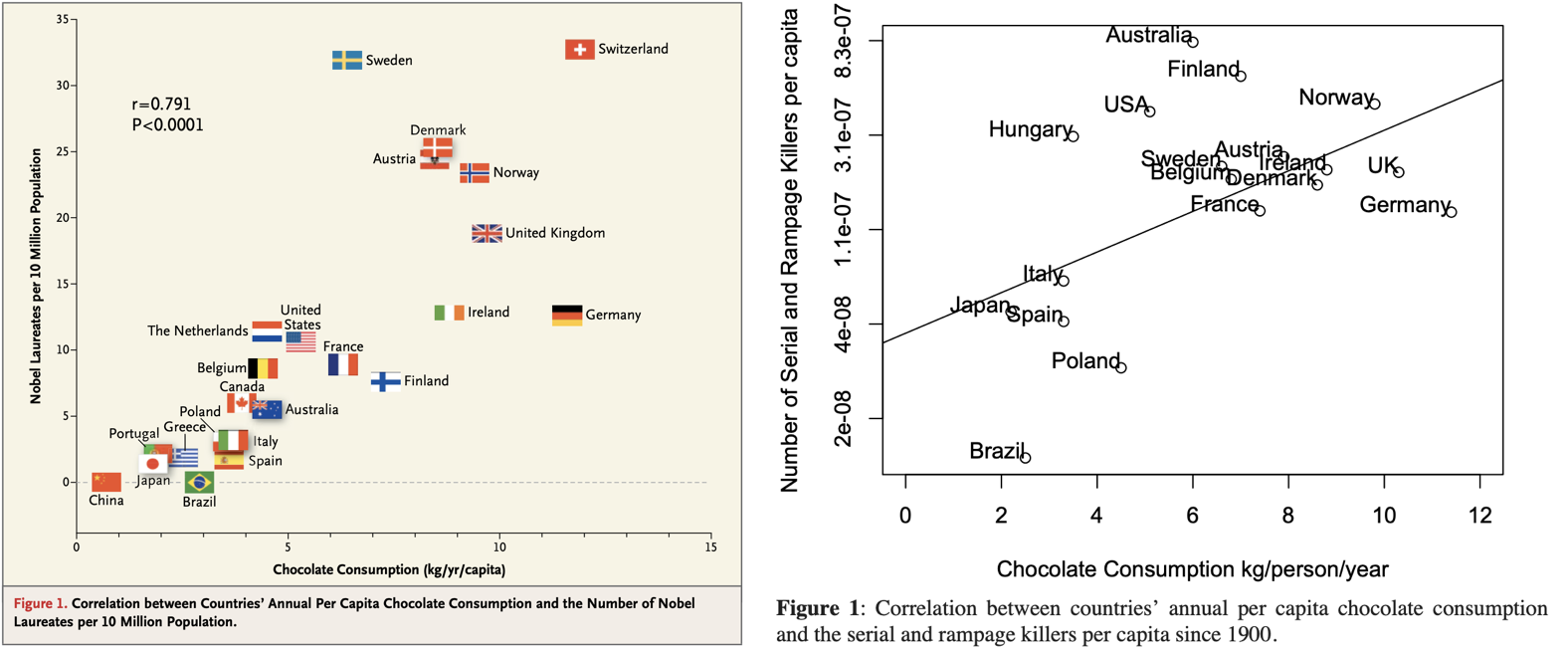
Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. N Engl J Med, 367(16), 1562-1564.
Winters, J. R., Roberts, S. G., & Braiding, D. S. Chocolate Consumption, Traffic Accidents and Serial Killers.
Erreur écologique / erreur atomiste
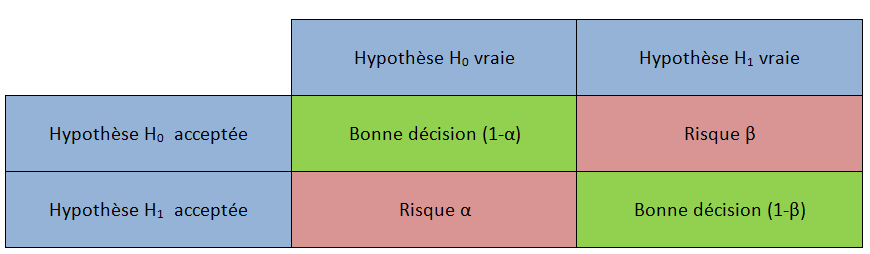
Risques d’erreur / p-value
Wikimedia Commons, CC BY-SA 4.0

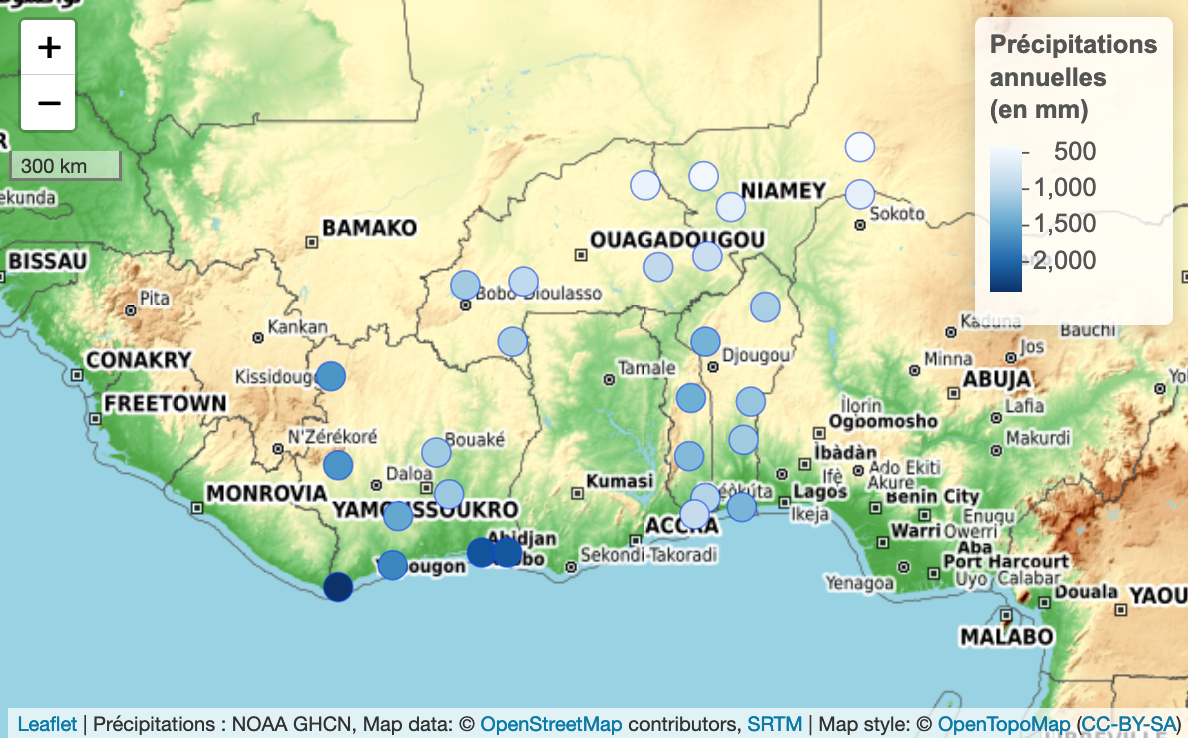
Exemple d’application : Précipitations en Afrique W
| id | name | latitude | longitude | elevation | preci_Y_5180 |
|---|---|---|---|---|---|
| BN000005306 | KANDI | 11.13 | 2.93 | 290 | 1091.171 |
| BN000005319 | NATITINGOU | 10.32 | 1.48 | 460 | 1372.879 |
| BN000005331 | TCHAOUROU | 8.87 | 2.60 | 325 | 1201.423 |
| BN000005335 | SAVE | 7.98 | 2.43 | 198 | 1144.021 |
| BN000005344 | COTONOU | 6.35 | 2.38 | 4 | 1348.521 |
| IV000005528 | ODIENNE | 9.50 | -7.57 | 432 | 1624.418 |
Données utilisées :
Précipitations annuelles sur la période 1951-1980
Source : Global Historical Climatology Network daily (GHCNd, lien)
traitements sur les données initiales : totaux annuels des précipitations pour les années complètes, sélection des stations où au moins 22 années sur 30
le jeu de données extrait comprend, au final, très peu de stations (28), en raison des lacunes dans les données.
1/ Graphique cartésien (nuage de points) pour avoir une idée de la forme, de l’intensité et du sens de la relation
Nuage de points ⭢ Hypothèses ⭢ Calcul du r ⭢ Significativité ⭢ Modélisation
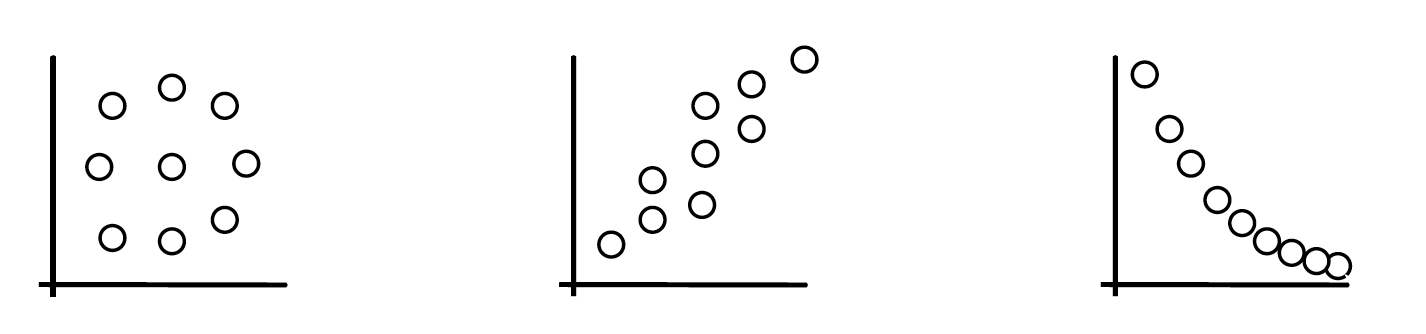
absence de relation
relation positive
linéaire
intensité moyenne
relation négative
non linéaire
intensité forte
Structure du code avec R-base :
plot(tableau$variableX, tableau$variableY) avec ggplot2 (comme ci-dessous) :
library()
# tableau : preci
# variableX : latitude (par ex), variableY : preci_Y_5180
ggplot(tableau) +
aes(x = variableX, y = variableY) +
geom_point(shape = "circle", size = 2, colour = "#112446") +
labs(x = "Variable X", y = "Variable Y")Sur l’exemple des précipitations :
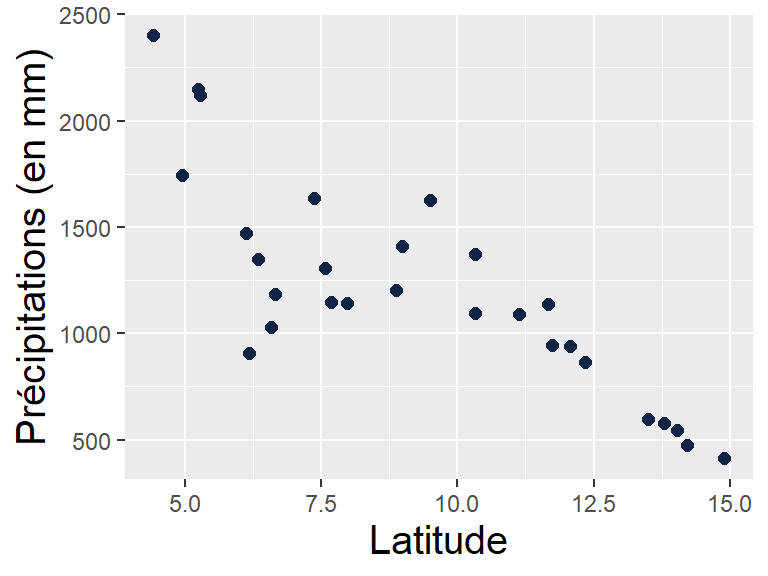
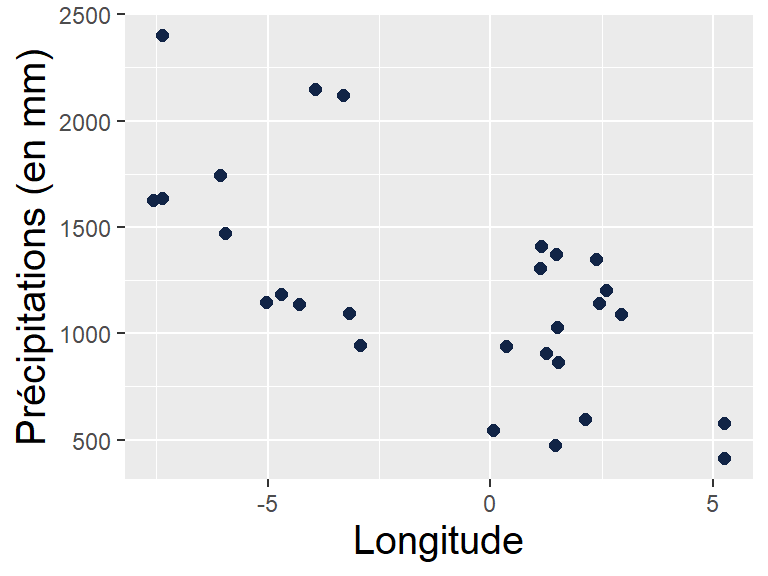
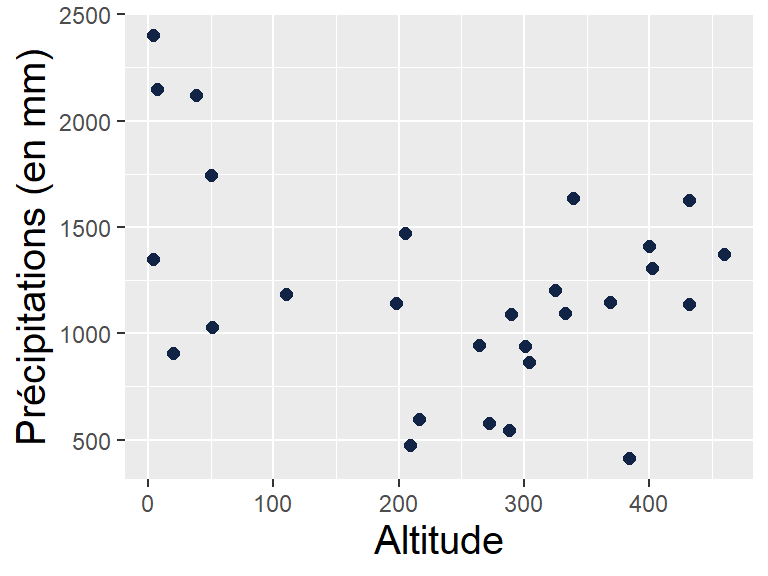
Source : NOAA GHCN
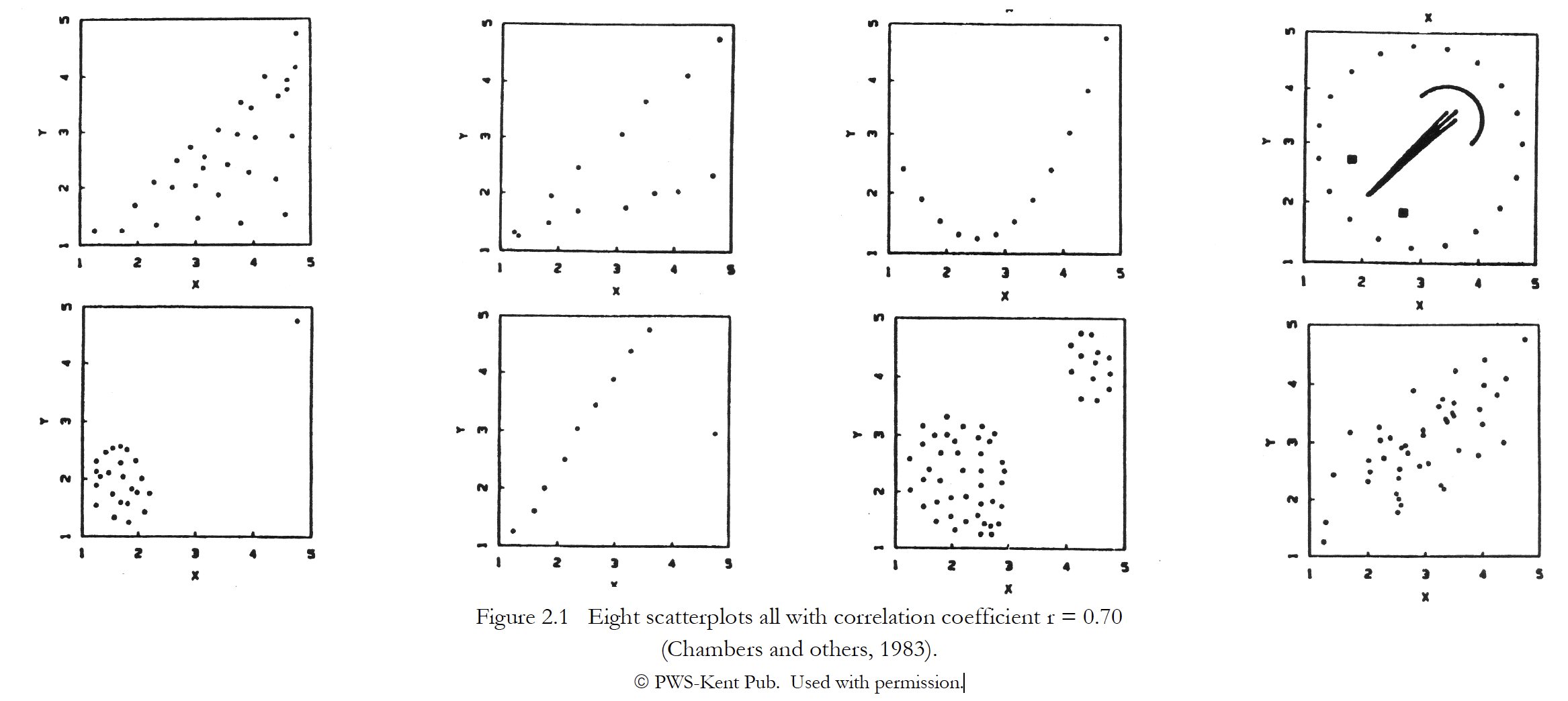
3/ Calcul d’un coefficient de corrélation
Nuage de points ⭢ Hypothèses ⭢ Calcul du r ⭢ Significativité ⭢ Modélisation
Coefficient de Bravais Pearson : \(r_{x,y}=\frac{cov_{x,y}}{\sigma_x.\sigma_y}\) avec \(cov_{x,y}=\frac1N\sum_{i=1}^{N}(x_i-\bar{x}).(y_i-\bar{y})\)

Extrait et adapté d’une illustration de Wikimedia Commons, DenisBoigelot, CC0
3/ Calcul d’un coefficient de corrélation
Nuage de points ⭢ Hypothèses ⭢ Calcul du r ⭢ Significativité ⭢ Modélisation
Coefficient de Bravais Pearson : \(r_{x,y}=\frac{cov_{x,y}}{\sigma_x.\sigma_y}\) avec \(cov_{x,y}=\frac1N\sum_{i=1}^{N}(x_i-\bar{x}).(y_i-\bar{y})\)
Tiré de Helsel, D.R., Hirsch, R.M. (2002). Statistical methods in water resources. Techniques of Water Resources Investigations. (lien vers le pdf)
4/ Vérification de la significativité
Nuage de points ⭢ Hypothèses ⭢ Calcul du r ⭢ Significativité ⭢ Modélisation
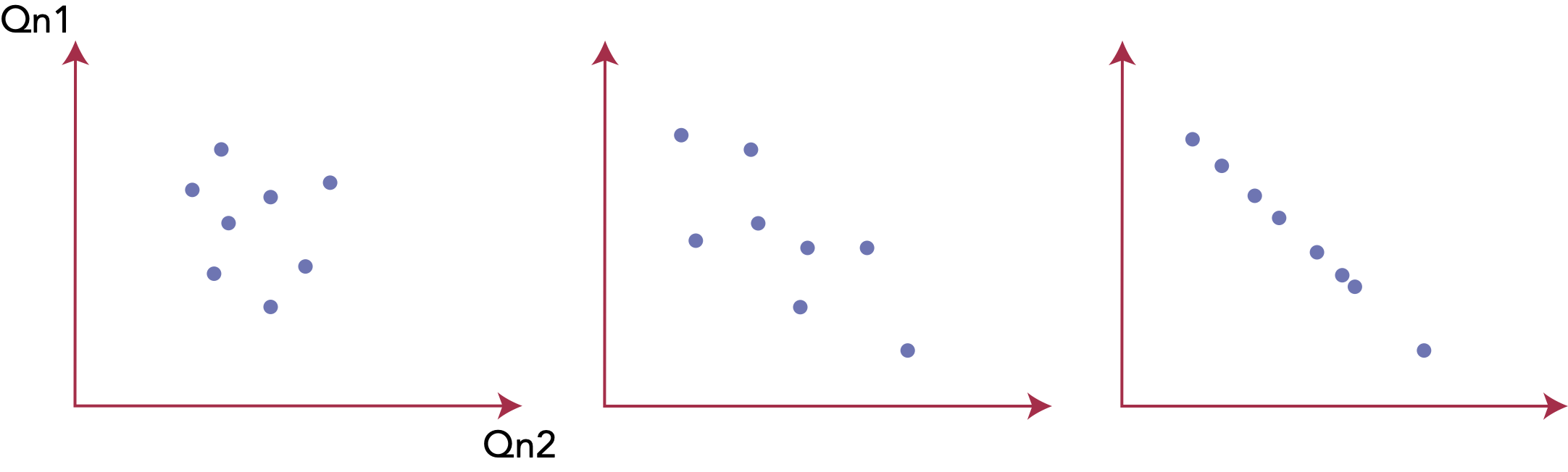
À gauche, on constate une absence de relation ; à droite une corrélation parfaite (négative). Entre ces deux situations, à partir de quand la relation est-elle significative ?
5/ Modélisation de la relation et analyse des résidus
Nuage de points ⭢ Hypothèses ⭢ Calcul du r ⭢ Significativité ⭢ Modélisation
Si relation, possibilité de réaliser une régression (y = ax + b) pour résumer, modéliser, prévoir…
Sous R :
lm_result <- lm(preci$preci_Y_5180 ~ preci$latitude )
lm_result
Call:
lm(formula = preci$preci_Y_5180 ~ preci$latitude)
Coefficients:
(Intercept) preci$latitude
2389.2 -127.1 plot(preci$preci_Y_5180 ~ preci$latitude)
abline(lm(preci$preci_Y_5180 ~ preci$latitude))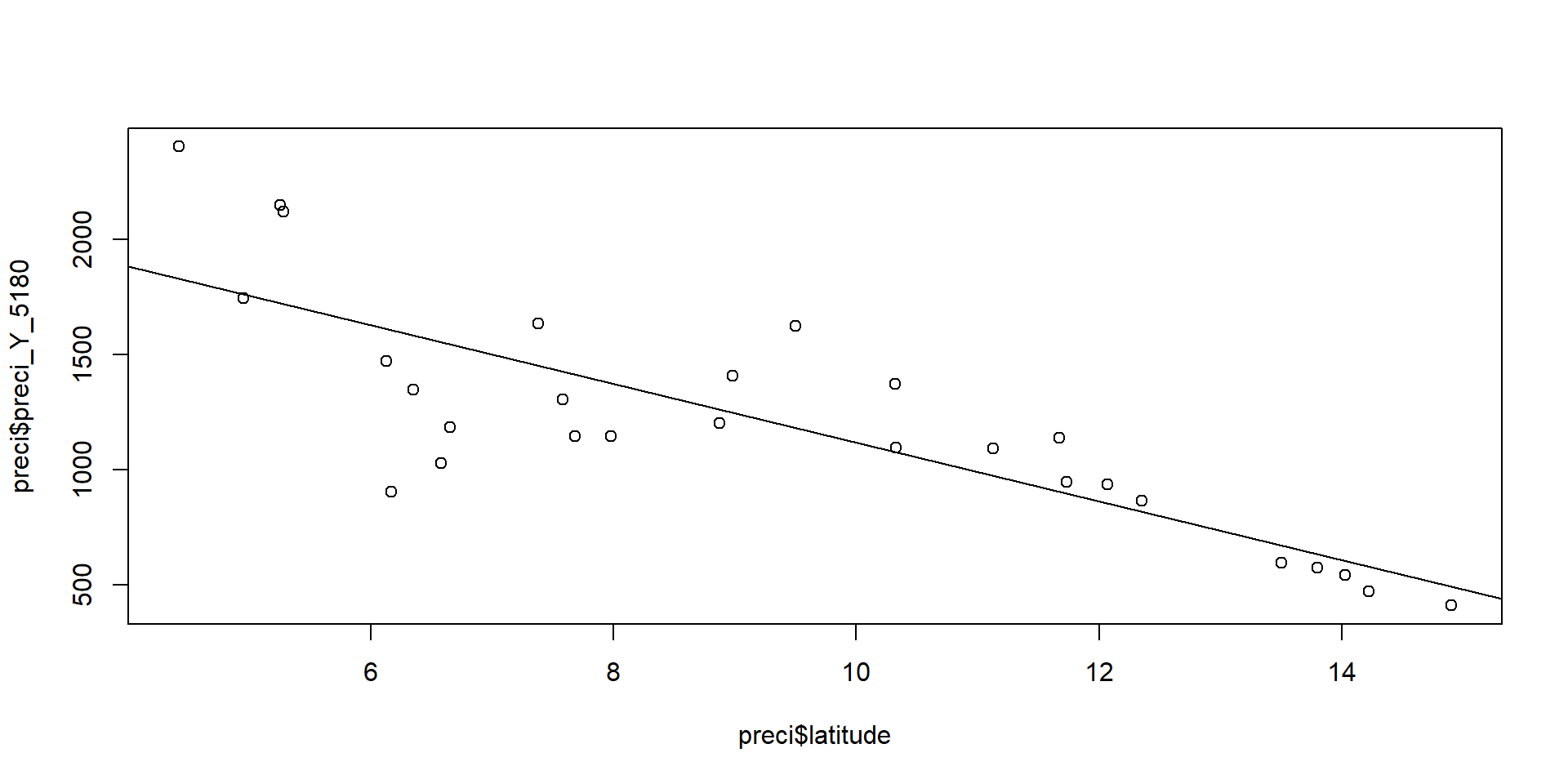
Le modèle Préci~Lat a un coefficient \(r\) de -0.82, donc un coefficient de détermination \(r^2\) de 0.67 : 67% de la variation des précipitations est liée à la latitude.
Analyse des résidus
Analyse très importante des résidus et de leur répartition spatiale => reflet de spécificités locales et/ou importance d’autres facteurs explicatifs
=> en l’occurrence, ici, pas top ! On constate une non homoscédasticité des résidus : la variance des résidus n’est pas constante selon la latitude (variable explicative).
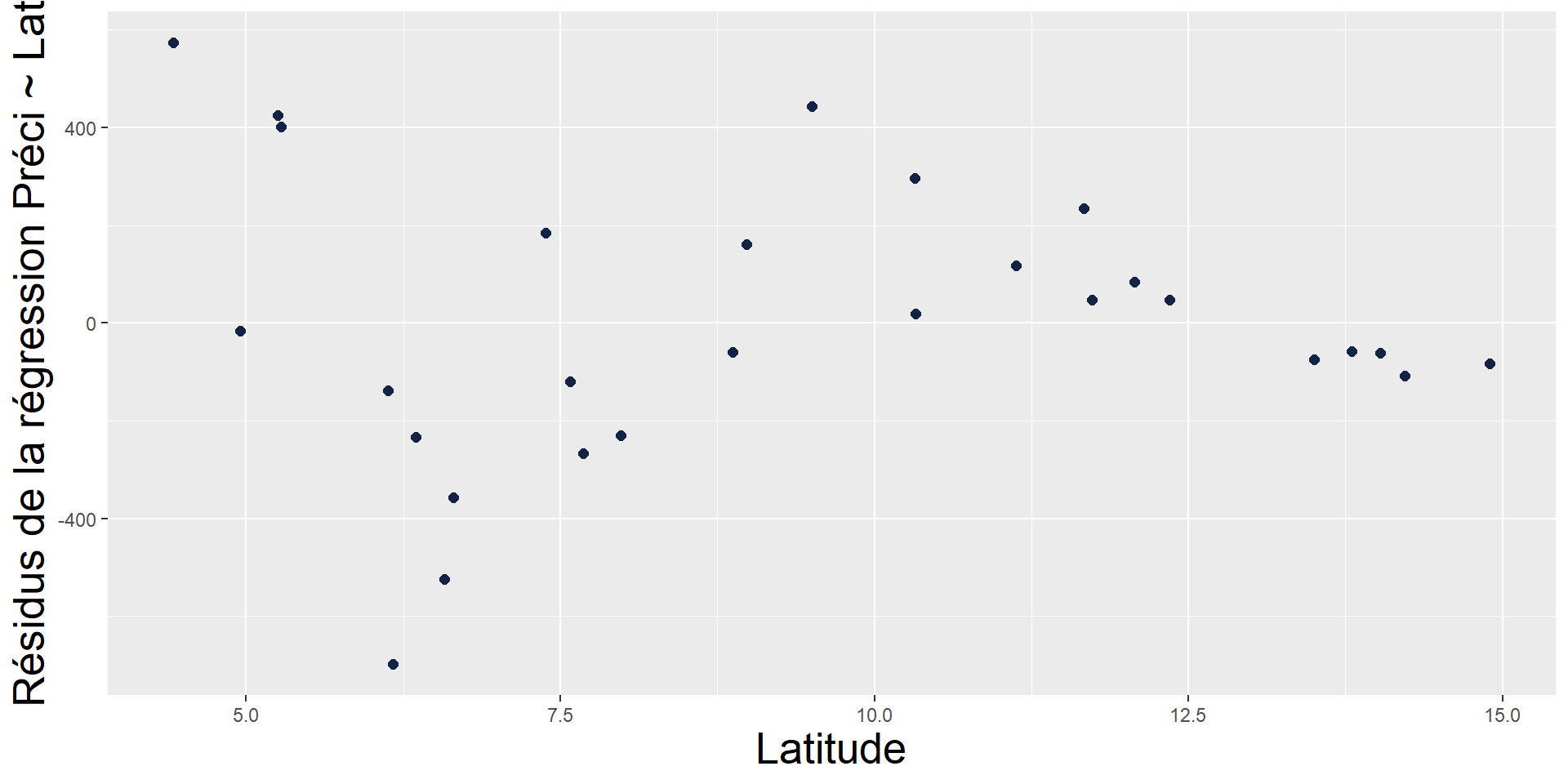
Sources : NOAA GHCN, OpenStreetMap, SRTM, OpenTopoMap (CC-BY-SA)
Conditions d’application
Pour au moins une des 2 variables, distribution normale et variance constante…

Source : xkcd (https://xkcd.com/605/)
Exemple d’application : le marché de Bouaké

à partir du tableau de données d’entrée de camion au marché de Bouaké (plus d’info)
Source : Bamba V., 2019. Transport et approvisionnement du marché de gros de Bouaké en produits vivriers. Thèse de Géographie, Université FHB de Cocody, Côte d’Ivoire.
traitements sur les données initiales : regroupement des produits en grandes catégories (ex. igname), sélection des principaux produits et modes de transport
le jeu de données extrait comprend 1409 enregistrements, soit 73% du jeu initial.
| code | produit | transport |
|---|---|---|
| 7 | igname | camion |
| 8 | igname | camion |
| 9 | igname | camion |
| 11 | arachide | voiture |
| 13 | riz | pick-up |
| 16 | igname | camion |
| 18 | riz | camion |
| 19 | igname | camion |
| 20 | igname | camion |
| 22 | arachide | voiture |
Quels sont les modes de transports par types de produits ?
et inversement ?
ggplot(bouake,
aes(x = produit,
fill = transport)) +
geom_bar(position = "stack") 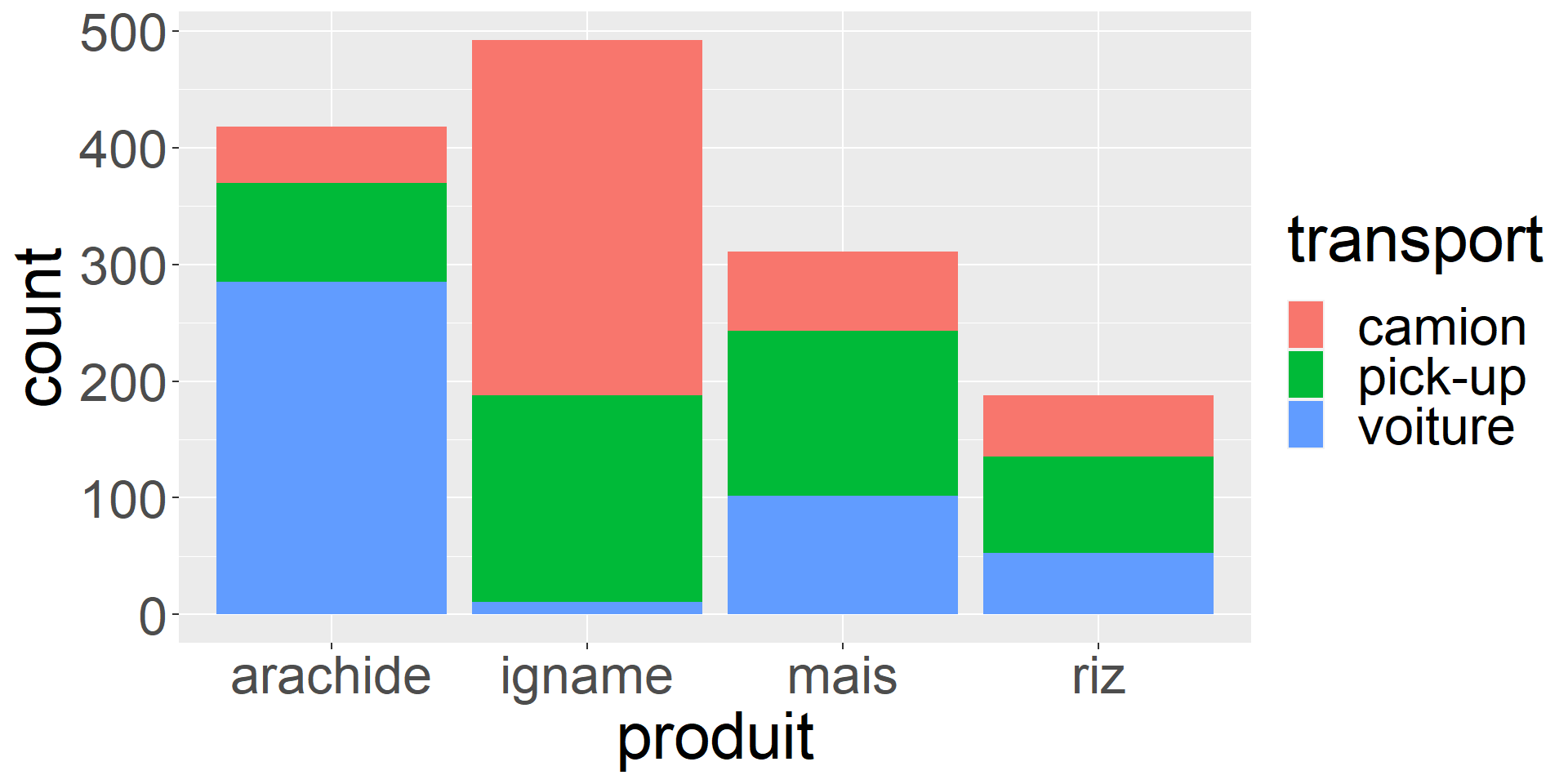
ggplot(bouake,
aes(x = transport,
fill = produit)) +
geom_bar(position = "stack")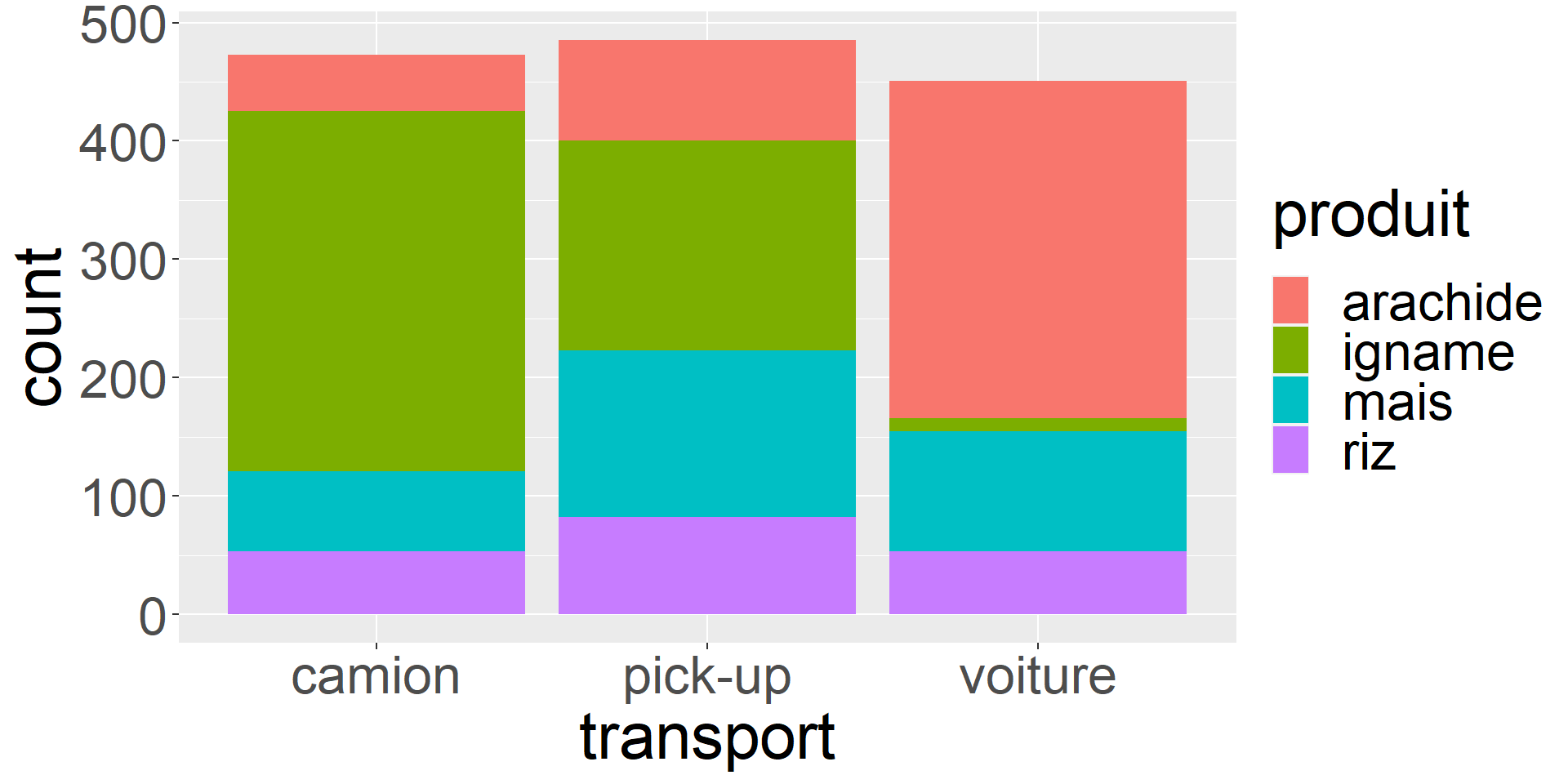
Tab. contingence & mosaïque ⭢ Hypothèses ⭢ \(\chi2\) observé ⭢ Significativité
Le graphique en mosaïque
Le graphique en mosaïque (ou le graphique Marimekko / Mekko) représente la proportion des individus pour toute combinaison/croisement de données qualitatives, par des rectangles dont la superficie est proportionnelle à cette proportion.
Sous R (base)1 :
mosaicplot(produit ~ transport,
data = bouake,
color = TRUE,
main = "Mosaic plot de Bouaké")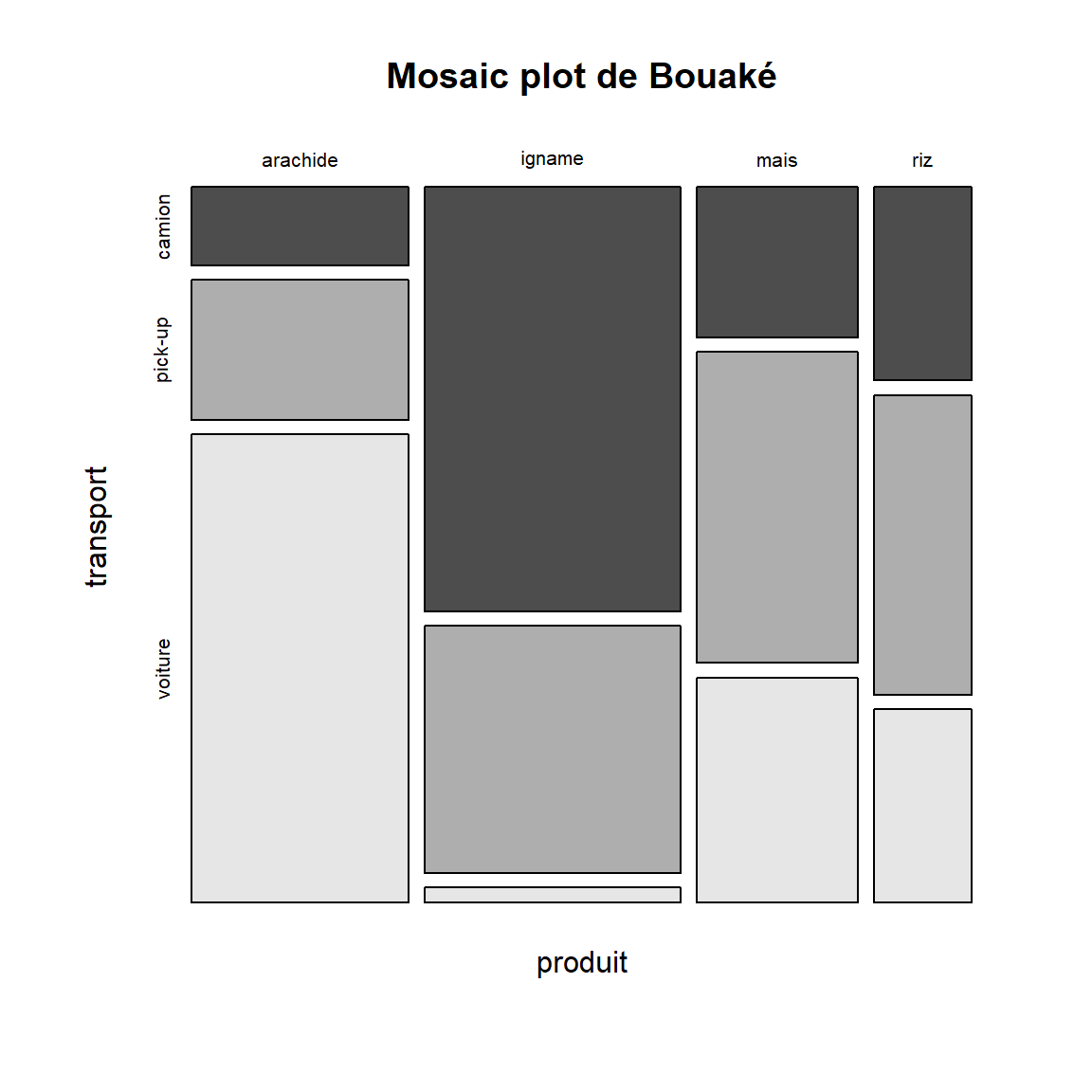
Le graphique en mosaïque
Le graphique en mosaïque (ou le graphique Marimekko / Mekko) représente la proportion des individus pour toute combinaison/croisement de données qualitatives, par des rectangles dont la superficie est proportionnelle à cette proportion.
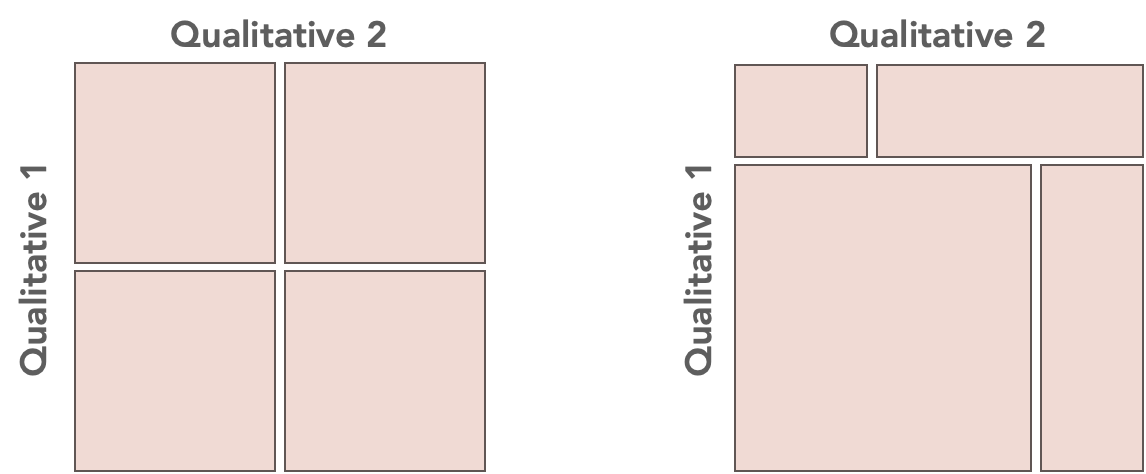
indépendance
relation ?
3/ Calcul du \(\chi2\) observé
Tab. contingence & mosaïque ⭢ Hypothèses ⭢ \(\chi2\) observé ⭢ Significativité
Calcul des effectifs théoriques : \(N^*_{ij} = \frac{ N_{i.} . N_{j.}}{ N_{..}}\) et des écarts à l’indépendance : \(DEV_{ij} = N_{ij} - N^*_{ij}\)
Puis calcul du \(\chi^2\) observé, qui est la somme des \(\chi_{ij}^2\) locaux :
\[\chi^2 obs. = \sum_{i=1,j=1}^{k,p} \chi_{ij}^2 = \sum_{1,1}^{k,p} \frac{DEV_{i,j}^2}{N^*_{i,j}}\]
Pour aller plus loin, quel est le sens de la relation ?
Il est possible de colorier les rectangles d’un graphique en mosaïque en fonction du degré de relation entre les variables : le bleu représente plus de cas que prévu étant donné l’indépendance, le rouge représente moins de cas que prévu.
mosaicplot(transport ~ produit, data = bouake,
main = "Relation entre types de produit et modes de transport des entrées au marché de Bouaké",
shade = TRUE)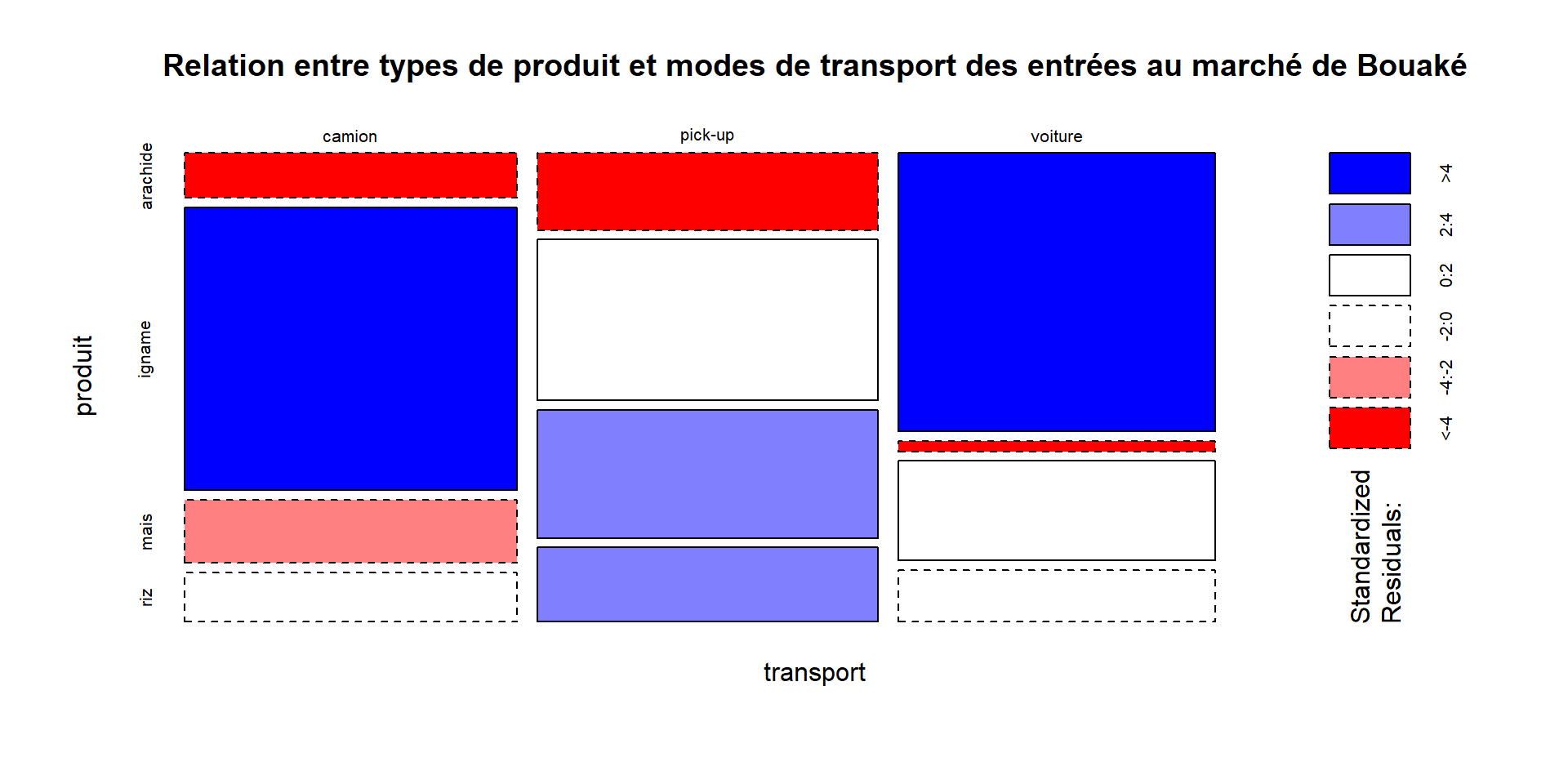
La question qu’on se pose…
Exemple d’application : îlot de chaleur à Lagos
L’îlot de chaleur urbain : températures de l’air la nuit plus élevées dans le centre des villes qu’à l’extérieur.
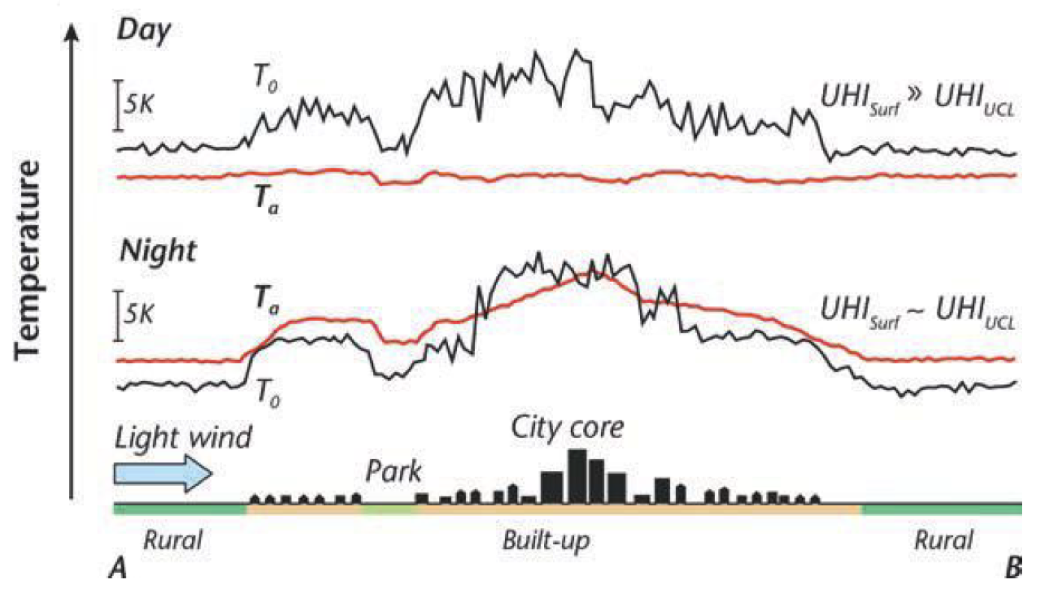
Oke et al., 2017
Autour de Lagos (~ 15 millions d’habitants, près de 23 millions pour l’agglomération)
Exemple d’application : deux sources utilisées
LST - Températures nocturnes de surface :
satellite MODIS Terra
Land Surface Temperature (MOD11A1)
1 nuit sélectionnée : 7/1/2023

NASA (domaine public)
LCZ - Local Climate Zones :
Demuzere et al., 2022
![]()

Bechtel et al., 2017
Ex. d’application : répartitions spatiales des LST et LCZ
Autour de Lagos
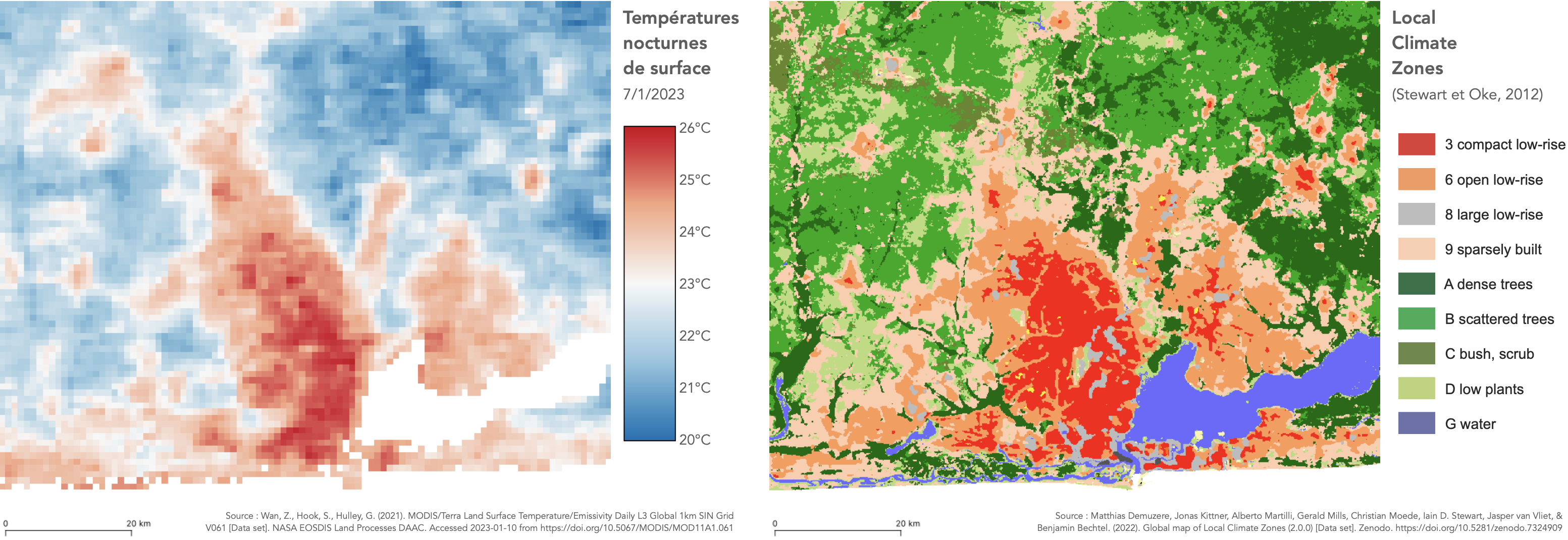
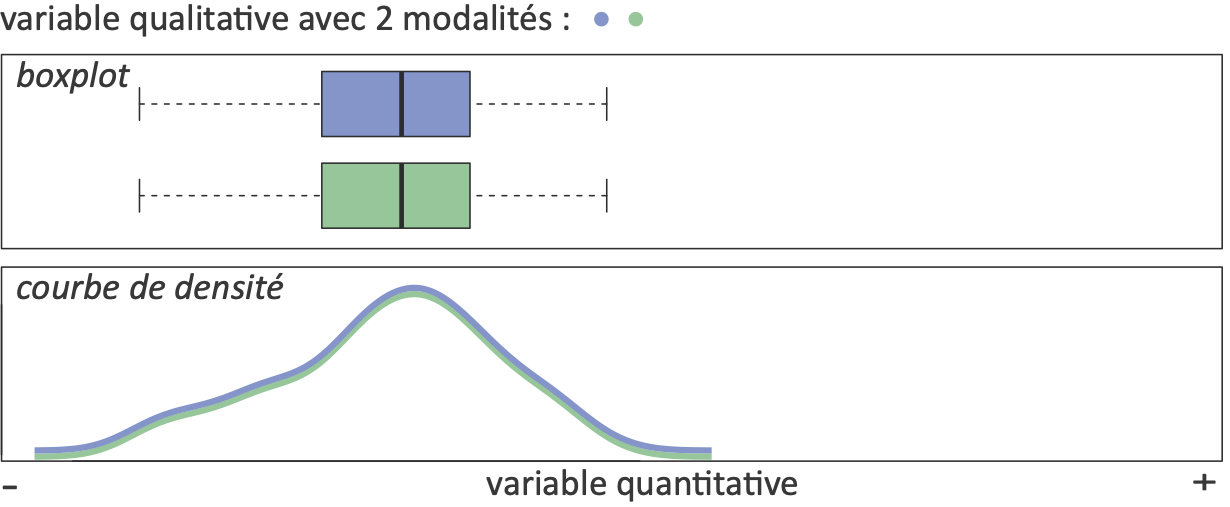
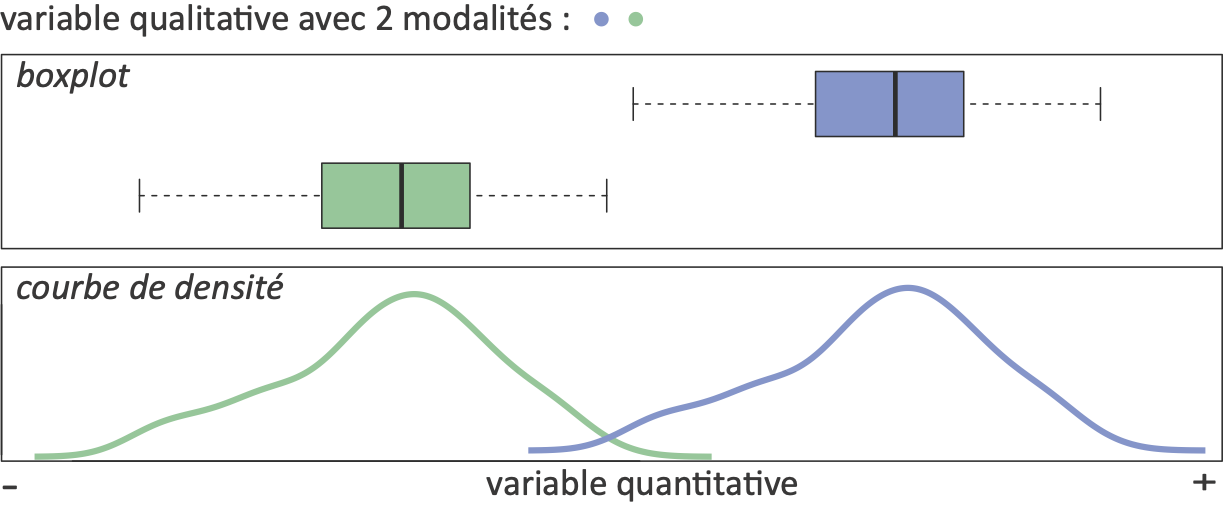
1/ Graphique des variations de Y selon les modalités de X
Graphique (boxplot) ⭢ Hypothèses ⭢ Calcul du T ou F observé ⭢ Significativité ⭢ Sens
Rappel : l’objectif est de visualiser la distribution de la variable quantitative selon les modalités de la variable qualitative.
Boxplot (ou boîte à moustache)
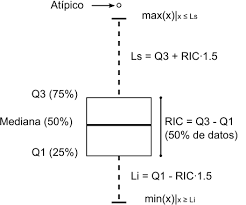
Wikimedia Commons, Jumanbar, CC BY-SA 3.0
Boxplot (ou boîte à moustache)
à partir du jeu de données R airquality
(Daily air quality measurements in New York, May to September 1973)
Avec R-base :
boxplot(airquality$Ozone ~ airquality$Month,
xlab="Var. Ql : mois",
ylab="Var. Qn : Concentrations en ozone (en ppm)")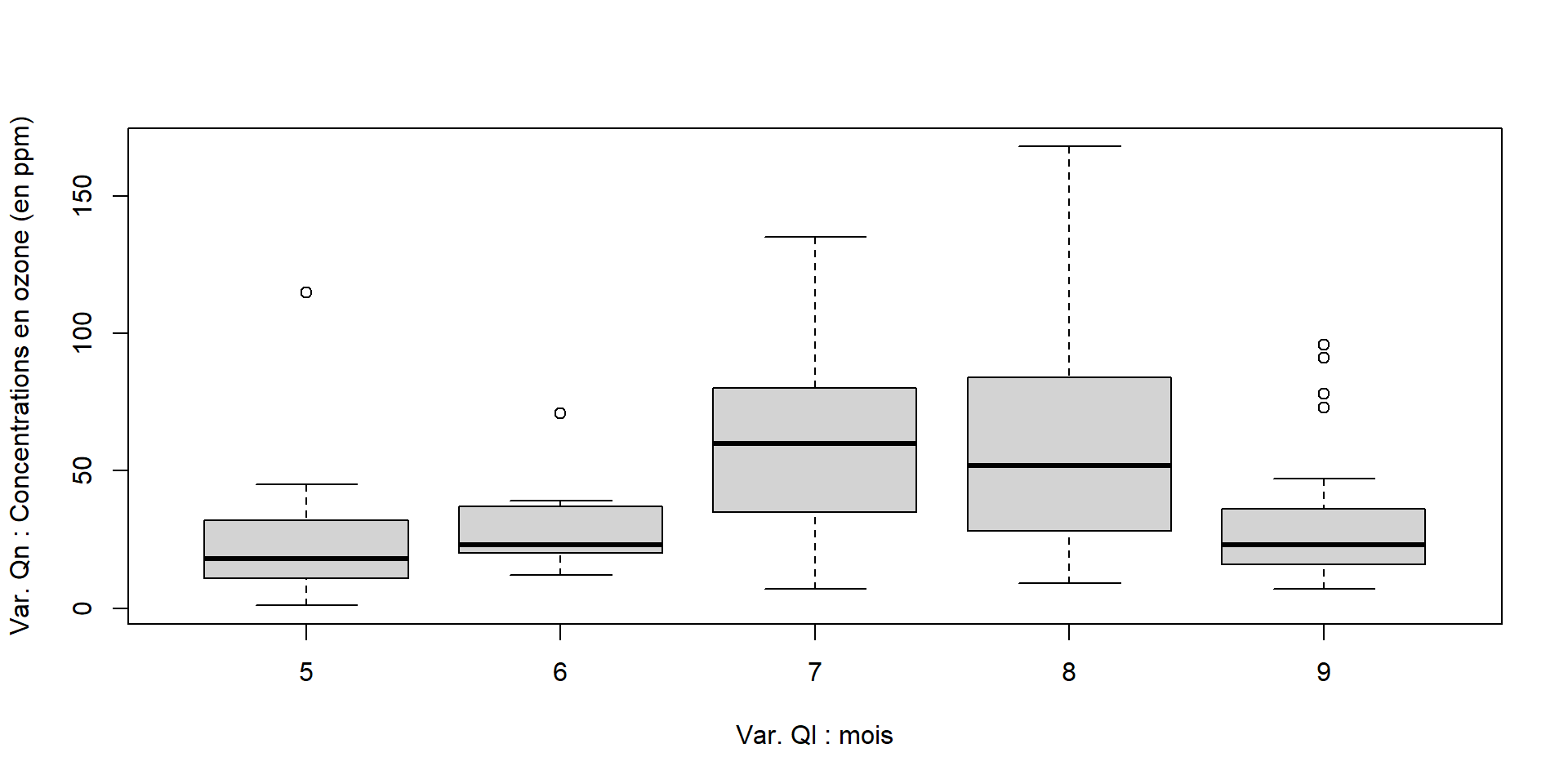
Avec ggplot2 :
ggplot(airquality,
aes(x = as.factor(Month),
y = Ozone)) +
xlab("Var. Ql : Mois") +
ylab("Var. Qn : Concentrations en ozone (en ppm)") +
geom_boxplot() 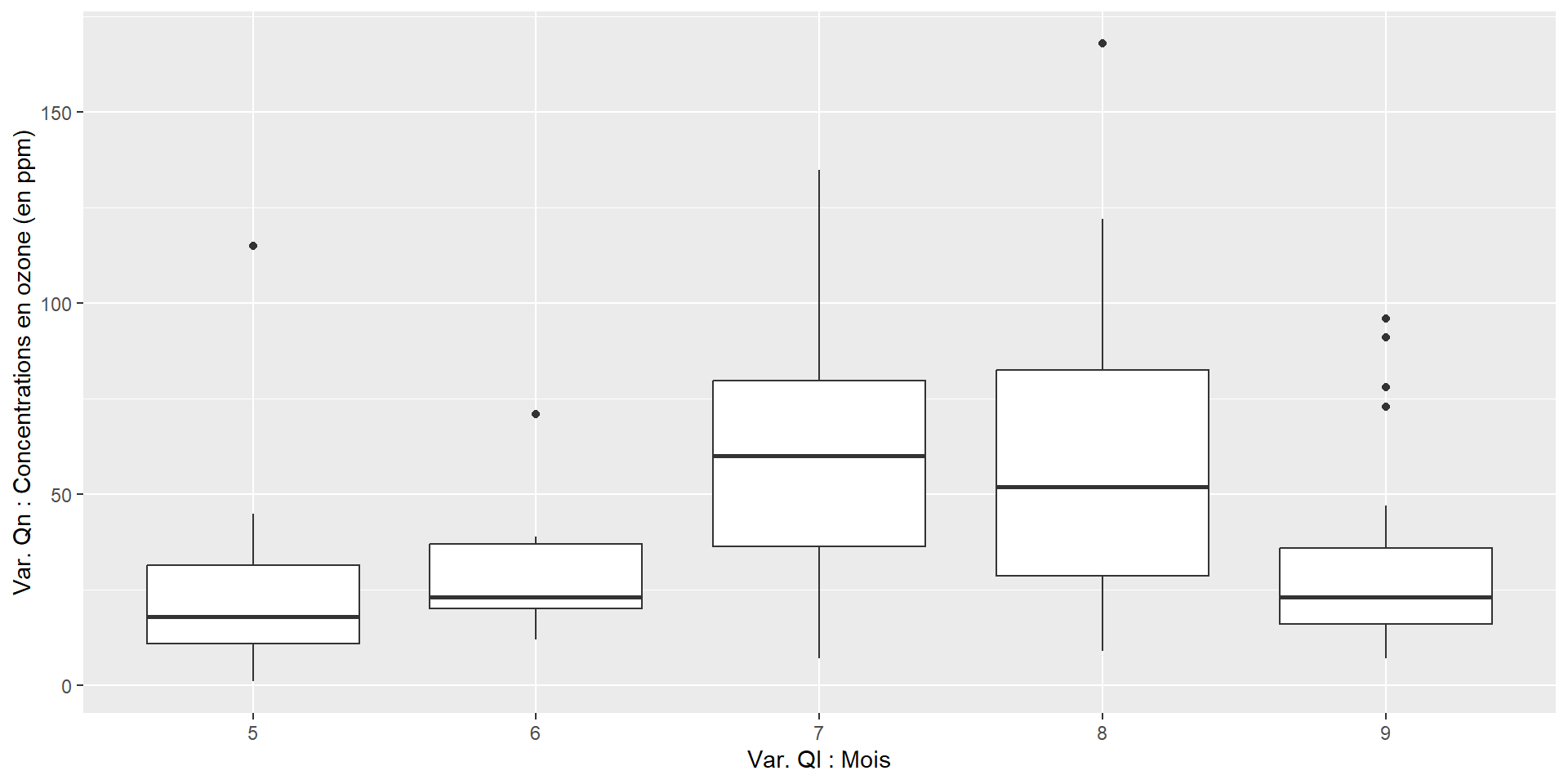
Boxplot (ou boîte à moustache) - variantes
Boxplot “à encoches”
ggplot(airquality, aes(x = as.factor(Month),
y = Ozone)) +
xlab("Var. Ql : Mois") +
ylab("Var. Qn : Concentrations en ozone (en ppm)") +
geom_boxplot(notch = TRUE,
fill = "cornflowerblue",
alpha = .7) 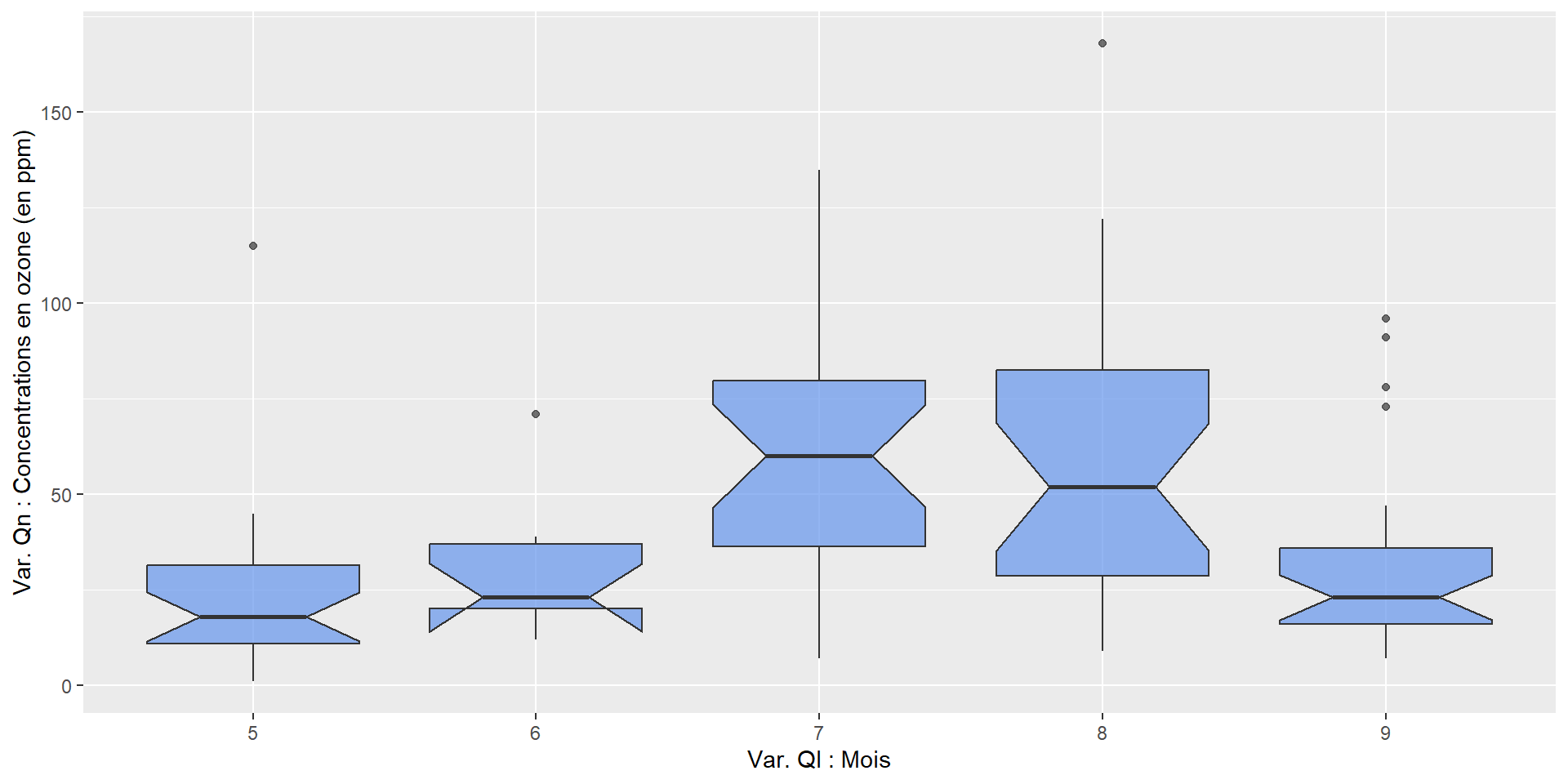
Boxplot “violon”
ggplot(airquality,
aes(x = as.factor(Month),
y = Ozone)) +
xlab("Var. Ql : Mois") +
ylab("Var. Qn : Concentrations en ozone (en ppm)") +
geom_violin() 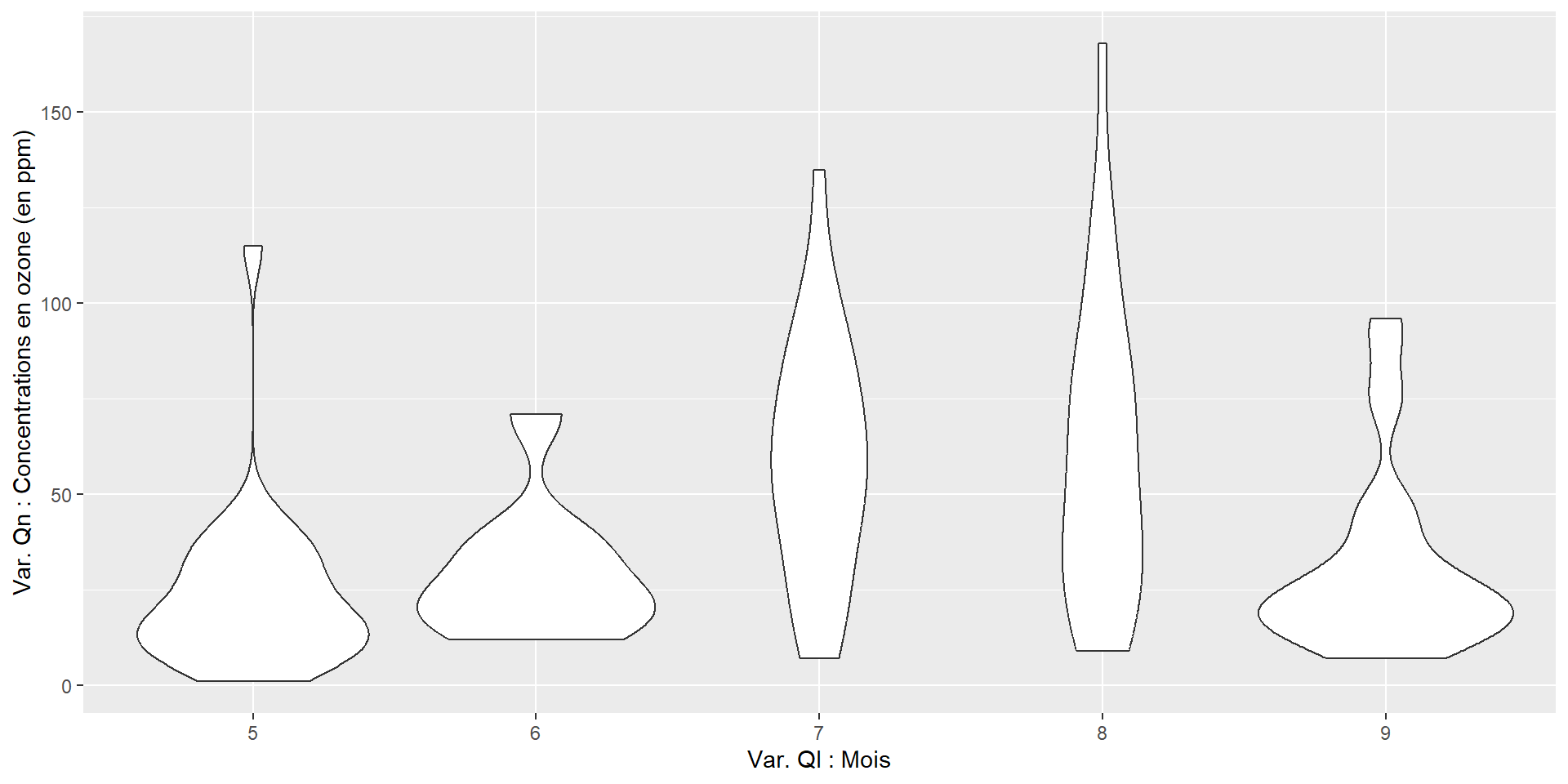
Autres variantes pour visualiser la distribution d’une var. Qn selon les modalités d’une var. Ql
Les lignes de crête Ridgeline plot
library(ggridges)
ggplot(airquality,
aes(x = Ozone,
y = as.factor(Month),
fill = as.factor(Month))) +
ylab("Var. Ql : Mois") +
xlab("Var. Qn : Concentrations en ozone (en ppm)") +
geom_density_ridges() +
theme_ridges() +
theme(legend.position = "none")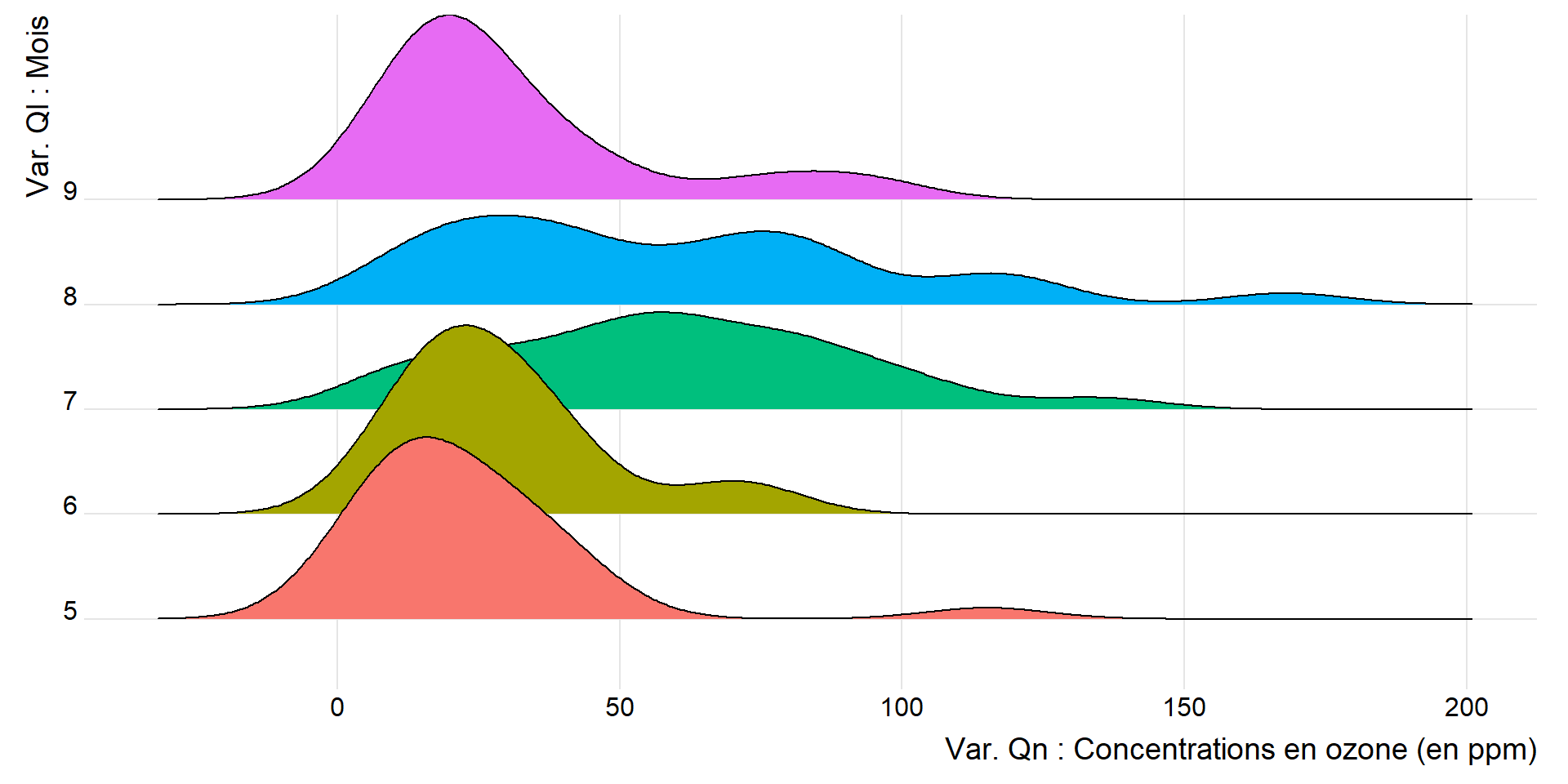
Les “gigues” Jitter plot
ggplot(airquality,
aes(y = as.factor(Month),
x = Ozone,
color = as.factor(Month))) +
geom_jitter(alpha = 0.7,
size = 3) +
labs(x = "Var. Qn : Concentrations en ozone (en ppm)",
y = "Var. Ql : Mois") +
theme_minimal() +
theme(legend.position = "none")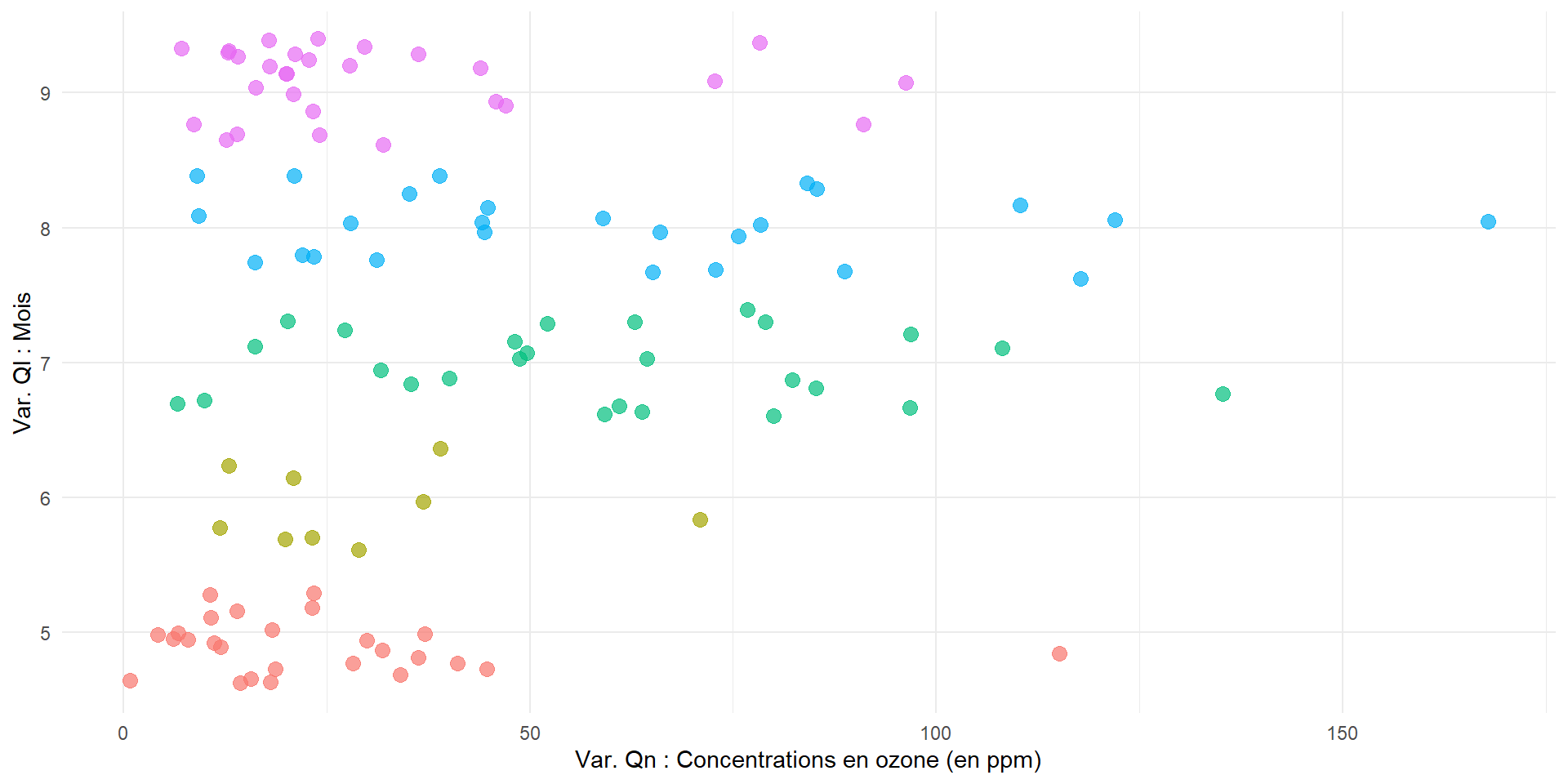
À partir de l’exemple d’application sur Lagos
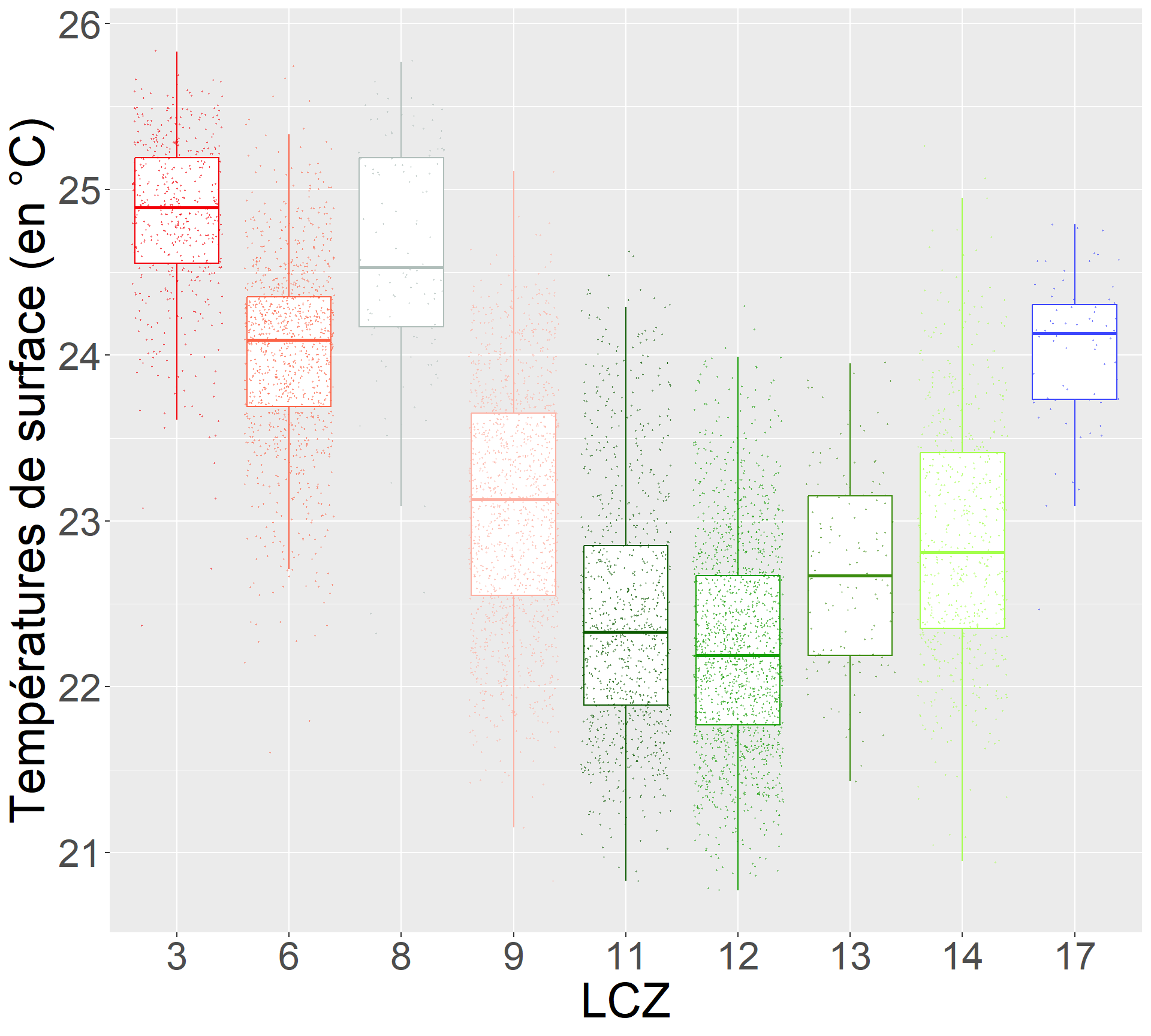
| LCZ | n | médiane | moyenne | écart-type |
|---|---|---|---|---|
| 3 - Compact low-rise | 498 | 24.9 | 24.8 | 0.5 |
| 6 - Open low-rise | 1056 | 24.1 | 24.0 | 0.6 |
| 8 - Large low-rise | 114 | 24.5 | 24.6 | 0.7 |
| 9 - Sparsely built | 1325 | 23.1 | 23.1 | 0.7 |
| 11 - Dense trees | 966 | 22.3 | 22.4 | 0.7 |
| 12 - Scattered trees | 1547 | 22.2 | 22.2 | 0.6 |
| 13 - Bush, scrub | 140 | 22.7 | 22.7 | 0.6 |
| 14 - Low plants | 577 | 22.8 | 22.9 | 0.7 |
| 17 - Water | 70 | 24.1 | 24.0 | 0.4 |
Avec une Ql à 2 modalités ou + : analyse de la variance et test de Fisher (F)
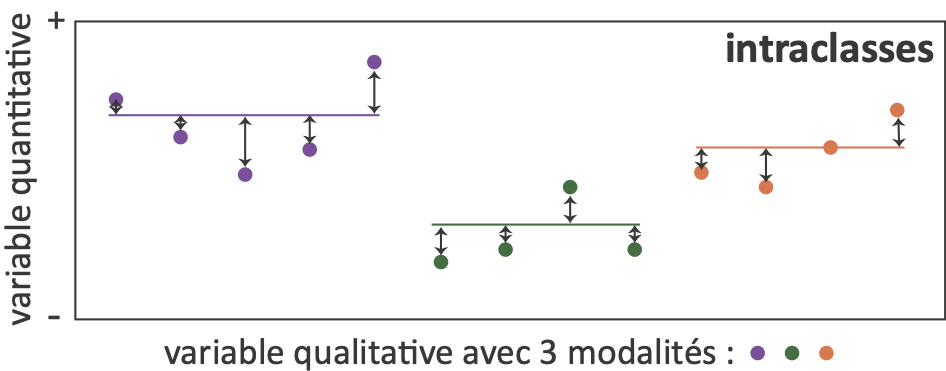
- Décomposition de la variance
Variance totale = Variance interclasses (expliquée) + Variance intraclasses (résiduelle)
\[\sum_{i=1}^{n}(X_i-\bar X)^2 = \sum_{g=1}^{k}(\bar X_g - \bar X)^2 + \sum_{g=1}^{k}\sum_{i=1}^{n_g}(X_i-\bar X_g)^2 \]
la variable quantitative (à expliquer) : \(X_i\) ; les modalités de la variable qualitative de \(g = 1\) à \(k\).
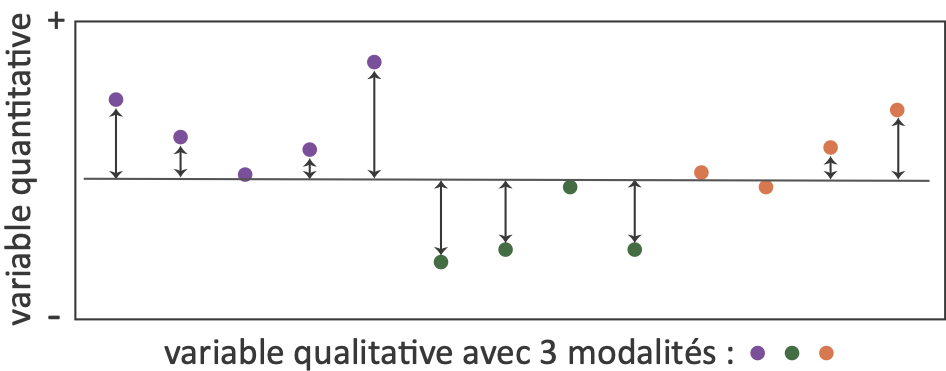
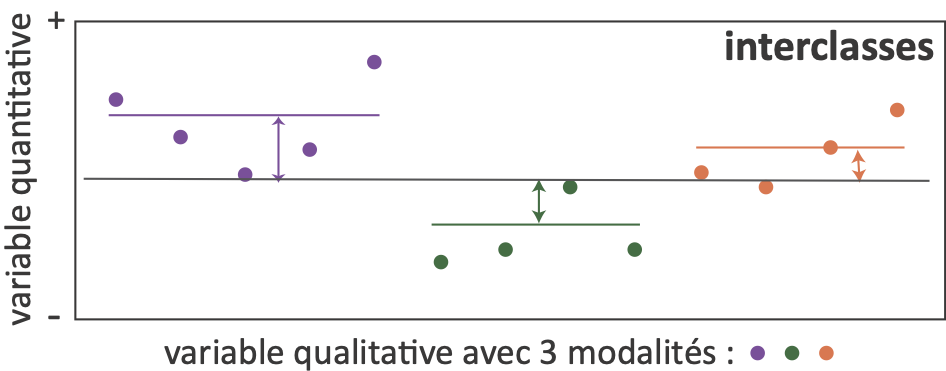
D’après Helsel, D.R., Hirsch, R.M. (2002). Statistical methods in water resources. Techniques of Water Resources Investigations. (lien vers le pdf)
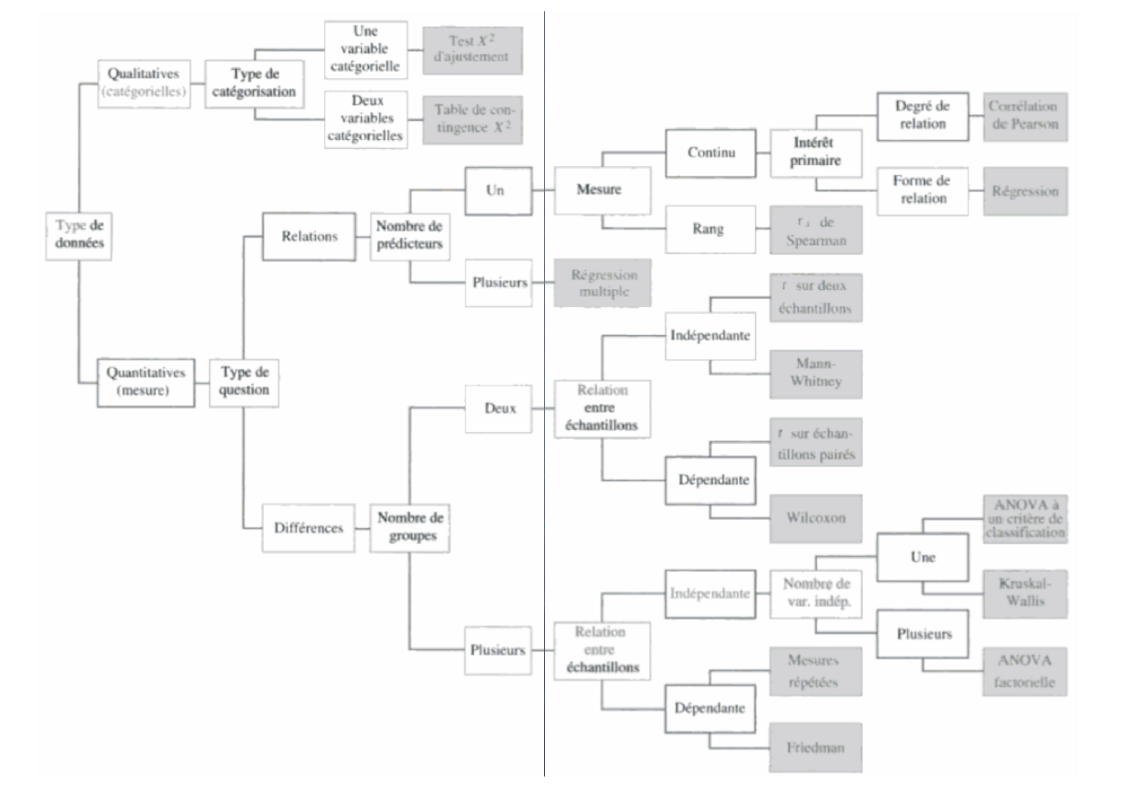
Howell, Méthodes statistiques en Sciences Humaines
Ressources
Helsel, D.R., Hirsch, R.M. (2002). Statistical methods in water resources. Techniques of Water Resources Investigations. (lien vers le pdf)
Vigneron, E. (1997). Géographie et Statistiques. PUF Coll. Que sais-je ?, n°3177.
Feuillet, T., Cossart, É., & Commenges, H. (2019). Manuel de géographie quantitative : Concepts, outils, méthodes. Armand Colin.
Denis, DJ. (2020). Univariate, bivariate, and multivariate statistics using R: quantitative tools for data analysis and data science. Wiley: Hoboken, NJ.
“C’est chi2 ? Et bien c’est lui !”, Grégoire Le Campion https://ouvrir.passages.cnrs.fr/wp-content/uploads/2019/09/X2.html
“Tout ce que vous n’avez jamais voulu savoir sur le χ2 sans jamais avoir eu envie de le demander”, Julien Barnier, 2008 http://cef-cfr.ca/uploads/Reference/khicarr%E92008.pdf
…
